最近团队在APM方向发力,需要在产品的深度学习模型的速度和占用空间大小两个维度来进行提升
目前使用的是Tensorflow Lite的格式在进行模型运算,想通过Tensorflow官方在2017年推出的预研项目XLA对模型进行优化,在官方示例过程的结论中模型使用XLA/AOT优化的模型比之前使用.pb格式的模型运行速度会提升10%~200%(有个别情况),占用空间会有4x的缩小
本文将逐一展示完整优化过程及遇到的坑(解决方案)。
Step -1: 使用XLA将模型编译为AOT(ahead-of-time)代码的步骤
编译tfcomfile
固化模型
graph.config.pbtxt
编写bazel BUILD脚本
编译对应平台二进制文件 .o .h
编写代码调用AOT模型
编写BUILD
编译对应平台最终产物 .so
环境
- Ubuntu18.04
- Bazel 0.24
- jdk 8
- NDK
- SDK
文件目录
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081//tensorflow/compiler/aot/│ aot_only_var_handle_op.cc│ benchmark.cc│ benchmark.h│ benchmark_main.template│ benchmark_test.cc│ BUILD│ codegen.cc│ codegen.h│ codegen_test.cc│ codegen_test_h.golden│ codegen_test_o.golden│ compile.cc│ compile.h│ embedded_protocol_buffers.cc│ embedded_protocol_buffers.h│ flags.cc│ flags.h│ test.cc│ test_graph_tfadd.config.pbtxt│ test_graph_tfadd.pbtxt│ test_graph_tfunknownop.config.pbtxt│ test_graph_tfunknownop.pbtxt│ test_graph_tfunknownop2.config.pbtxt│ test_graph_tfunknownop3.config.pbtxt│ tfcompile.bzl│ tfcompile_main.cc│├─custom│ │ BUILD│ │ com_qihoo_cleandroid_sdk_imageclassfier_core_classfier_process_CustomClassifier.cc│ │ com_qihoo_cleandroid_sdk_imageclassfier_core_classfier_process_CustomClassifier.h│ │ custom_interface.config.pbtxt│ │ custom_interface_lib.h│ │ custom_interface_tfcompile_function.o│ │ custom_interface_tfcompile_metadata.o│ │ debug.cc│ │ debug.h│ │ figure-65.png│ │ figure-66.jpg│ │ frozen_custom_010.pb│ │ input_image.py│ │ libcustom_interface.a│ │ libcustom_interface.pic.a│ │ libcustom_interface.so│ │ lib_custom_interface.so│ │ log.h│ │ log_stream.h│ │ out.h│ │ out_helper.o│ │ out_model.o│ │ predict_model.py│ │ Screenshot_67.jpg│ │ Screenshot_68.png│ │ tfcompile_h_o.py│ │ __init__.py│ ││ ├─arm64-v8a│ │ libcustom_interface.so│ │ lib_custom_interface.so│ ││ └─armeabi-v7a│ libcustom_interface.so│ lib_custom_interface.so│└─testsBUILDmake_test_graphs.pytest_graph_tfadd.config.pbtxttest_graph_tfadd_with_ckpt.config.pbtxttest_graph_tfassert_eq.config.pbtxttest_graph_tfcond.config.pbtxttest_graph_tffunction.config.pbtxttest_graph_tfgather.config.pbtxttest_graph_tfmatmul.config.pbtxttest_graph_tfmatmulandadd.config.pbtxttest_graph_tfsplits.config.pbtxttest_graph_tftop_k.config.pbtxttest_graph_tfvariable.config.pbtxttest_graph_tfvariable_sequential_updates.config.pbtxttfcompile_test.cc
Step 0: 编译tfcomfile
首先编译tfcomfile其实就是编译tensorflow源码中的一部分,但这一部分的编译却需要整个工程的依赖
下载源码
1git clone --recurse-submodules https://github.com/tensorflow/tensorflow其中–recurse-submodules参数是必须的,用于获取TensorFlow依赖的protobuf库.
配置TensorFlow
12cd ~/tensorflow./configure需要注意配置编译项的一些规则
123456789101112131415161718192021222324252627282930313233343536373839404142You have bazel 0.25.0 installed.Please specify the location of python. [Default is C:\ProgramData\Anaconda3\python.exe]:Found possible Python library paths:C:\ProgramData\Anaconda3\lib\site-packagesPlease input the desired Python library path to use. Default is [C:\ProgramData\Anaconda3\lib\site-packages]Do you wish to build TensorFlow with XLA JIT support? [y/N]: YXLA JIT support will be enabled for TensorFlow.Do you wish to build TensorFlow with ROCm support? [y/N]: NNo ROCm support will be enabled for TensorFlow.Do you wish to build TensorFlow with CUDA support? [y/N]: NNo CUDA support will be enabled for TensorFlow.Please specify optimization flags to use during compilation when bazel option "--config=opt" is specified [Default is/arch:AVX]:Would you like to override eigen strong inline for some C++ compilation to reduce the compilation time? [Y/n]: NNot overriding eigen strong inline, some compilations could take more than 20 mins.Preconfigured Bazel build configs. You can use any of the below by adding "--config=<>" to your build command. See .bazelrc for more details.--config=mkl # Build with MKL support.--config=monolithic # Config for mostly static monolithic build.--config=gdr # Build with GDR support.--config=verbs # Build with libverbs support.--config=ngraph # Build with Intel nGraph support.--config=numa # Build with NUMA support.--config=dynamic_kernels # (Experimental) Build kernels into separate shared objects.--config=v2 # Build TensorFlow 2.x instead of 1.x.Preconfigured Bazel build configs to DISABLE default on features:--config=noaws # Disable AWS S3 filesystem support.--config=nogcp # Disable GCP support.--config=nohdfs # Disable HDFS support.--config=noignite # Disable Apache Ignite support.--config=nokafka # Disable Apache Kafka support.--config=nonccl # Disable NVIDIA NCCL support.Configuration finished最需要注意的是其中的:
Do you wish to build TensorFlow with XLA JIT support? [y/N]: Y!!!这是使用XLA的关键开始编译tfcompile
tfcompile的Bazel脚本入口在
//tensorflow/compiler/aot:tfcompile执行命令进行编译
1bazel build //tensorflow/compiler/aot:tfcompile
讲一下这一步骤中遇到的坑
- 首先编译源码的过程中不同资源是异步编译的经常会出现找不到包的问题,可以多尝试执行上一命令重复进行编译即可
- 在编译过程中会首先去请求下载各种依赖,这一过程中会出现依赖方已升级版本但本地请求需要验证SHA256(本地SHA256是在代码中写死的)不匹配这一问题,可以根据日志定位依赖下载脚本位置修改对应SHA256值即可
- bazel编译过程在下载依赖后是有缓存机制的不必担心下载后的依赖丢失(前提是不执行
bazel clean) - 在编译tfcompile过程中如果遇到不论在什么网络状态在都无法编译通过的问题尝试
bazel clean后重新执行命令或在项目根目录执行bazel build --config=opt //tensorflow/tools/pip_package:build_pip_package进行依赖下载构建依赖包成功后再次执行tfcompile编译命令就会顺畅很多
Step 1: 固化模型
这一步中需要将graph与checkpoints冻结形成.pb格式的固化模型这是之后形成二进制文件的原料
这一步很容易没有什么坑 ;)
Step 2: graph.config.pbtxt
这一步中主要是为了形成graph的描述,即注明该graph的输入节点的节点名、入参tensor大小,输出节点的节点名等参数
有两种方式可以形成该描述
使用源码中的工具进行自动化形成(需要编写代码)
使用源码中的tf2xla_pb2.py可进行一些操作形成该描述
这里介绍另一种直观且快速的方式
通过可视化工具确定入口出口

通过该工具将模型导入后可扩展内部所有节点的描述,即可以得到输入节点与输出节点的描述,进行对应节点描述文件编写
123456789101112131415161718# Each feed is a positional input argument for the generated function. The order# of each entry matches the order of each input argument. Here “x_hold” and “y_hold”# refer to the names of placeholder nodes defined in the graph.feed {id { node_name: "input" }shape {dim { size: 1 }dim { size: 160 }dim { size: 160 }dim { size: 3 }}}# Each fetch is a positional output argument for the generated function. The order# of each entry matches the order of each output argument. Here “x_y_prod”# refers to the name of a matmul node defined in the graph.fetch {id { node_name: "MobilenetV2/Predictions/Reshape_1" }}
将该文件保存为graph.config.pbtxt
该步骤完成
WARNING: 需要注意在该描述文件中添加注释时只可使用#作为标示,否则编译不过且定位不到问题位置
Step 3: 编写bazel BUILD脚本
在这一步骤中将进行编写编译脚本很简短的配置但有一些细节需要注意:
建议在
//tensorflow/compiler/aot下建立自己的floder将以上生成的产物放入其中,以下操作默认操作在//tensorflow/compiler/aot/custom下进行在custom目录下创建BUILD脚本文件
1234567891011load("//tensorflow/compiler/aot:tfcompile.bzl", "tf_library")tf_library(name = "custom_interface",cpp_class = "Classifier",graph = "frozen_custom_010.pb",config = "graph.config.pbtxt",)内部参数解释:
name:即执行编译后将生成产物的名称cpp_class:即生成C++头文件.h中对该类的命名,可以在该类名前添加作用域such as:foo::bar::Classifier等自定义操作graph:即之前步骤中生成的冻结图.pb产物config:即上一步骤中产生的图描述文件此步骤完成
Step 4: 编译对应平台二进制文件 .o .h
使用命令:bazel build --verbose_failures //tensorflow/compiler/aot/custom:custom_interface
其中custom_interface对应上一步骤中的name
鉴于之前编译过tfcompile,此步骤只是使用了该产物中的部分资源进行编译所以不会有什么坑
这里介绍另一种编译此步骤产物的方式,需要在编译tfcompile步骤后产生的bazel-bin文件中找到tfcompile的run文件
通过命令tfcompile --graph=frozen_custom_010.pb --config=graph.config.pbtxt --cpp_class="Classifier"
这里贴下tfcompile的具体用法其中具有编译对应平台ABI的参数:
|
|
最终生成三个产物:
cat custom_interface_lib.h:123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148149150151152153154155156157158159160161162163164165166167168169170171172173174175176177178179180181182183184185186187188189190191192193194195196197198199200201202203204205206207208209210211212213214215216217218219220221222223224225226227228229230231232233234235236237238239240241242243244245246247248249250251252253254255256257258259260261262263264265266267268269270271272273274275276277278279280281282283284285286287// Generated by tfcompile, the TensorFlow graph compiler. DO NOT EDIT!//// This header was generated via ahead-of-time compilation of a TensorFlow// graph. An object file corresponding to this header was also generated.// This header gives access to the functionality in that object file.//// clang-format offnamespace Eigen { struct ThreadPoolDevice; }namespace xla { class ExecutableRunOptions; }// (Implementation detail) Entry point to the function in the object file.extern "C" void __xla_tensorflow_compiler_aot_custom__custom_interface(void* result, const ::xla::ExecutableRunOptions* run_options,const void** args, void** temps, tensorflow::int64* profile_counters);// Classifier represents a computation previously specified in a// TensorFlow graph, now compiled into executable code. This extends the generic// XlaCompiledCpuFunction class with statically type-safe arg and result// methods. Usage example://// Classifier computation;// // ...set args using computation.argN methods// CHECK(computation.Run());// // ...inspect results using computation.resultN methods//// The Run method invokes the actual computation, with inputs read from arg// buffers, and outputs written to result buffers. Each Run call may also use// a set of temporary buffers for the computation.//// By default each instance of this class manages its own arg, result and temp// buffers. The AllocMode constructor parameter may be used to modify the// buffer allocation strategy.//// Under the default allocation strategy, this class is thread-compatible:// o Calls to non-const methods require exclusive access to the object.// o Concurrent calls to const methods are OK, if those calls are made while it// is guaranteed that no thread may call a non-const method.//// The logical function signature is:// (arg0: f32[1,160,160,3]) -> (f32[1,30])//// Memory stats:// arg bytes total: 307200// arg bytes aligned: 307200// temp bytes total: 4143008// temp bytes aligned: 4143104class Classifier final : public tensorflow::XlaCompiledCpuFunction {public:// Number of input arguments for the compiled computation.static constexpr size_t kNumArgs = 1;// Byte size of each argument buffer. There are kNumArgs entries.static const ::tensorflow::int64 ArgSize(::tensorflow::int32 index) {return BufferInfos()[ArgIndexToBufferIndex()[index]].size();}// Returns static data used to create an XlaCompiledCpuFunction.static const tensorflow::XlaCompiledCpuFunction::StaticData& StaticData() {static XlaCompiledCpuFunction::StaticData* kStaticData = [](){XlaCompiledCpuFunction::StaticData* data =new XlaCompiledCpuFunction::StaticData;set_static_data_raw_function(data, __xla_tensorflow_compiler_aot_custom__custom_interface);set_static_data_buffer_infos(data, BufferInfos());set_static_data_num_buffers(data, kNumBuffers);set_static_data_arg_index_table(data, ArgIndexToBufferIndex());set_static_data_num_args(data, kNumArgs);set_static_data_result_index(data, kResultIndex);set_static_data_arg_names(data, StaticArgNames());set_static_data_result_names(data, StaticResultNames());set_static_data_program_shape(data, StaticProgramShape());set_static_data_hlo_profile_printer_data(data, StaticHloProfilePrinterData());return data;}();return *kStaticData;}Classifier(AllocMode alloc_mode =AllocMode::ARGS_VARIABLES_RESULTS_PROFILES_AND_TEMPS): XlaCompiledCpuFunction(StaticData(), alloc_mode) {}Classifier(const Classifier&) = delete;Classifier& operator=(const Classifier&) = delete;// Arg methods for managing input buffers. Buffers are in row-major order.// There is a set of methods for each positional argument, with the following// general form://// void set_argN_data(void* data)// Sets the buffer of type T for positional argument N. May be called in// any AllocMode. Must be called before Run to have an affect. Must be// called in AllocMode::RESULTS_PROFILES_AND_TEMPS_ONLY for each positional// argument, to set the argument buffers.//// T* argN_data()// Returns the buffer of type T for positional argument N.//// T& argN(...dim indices...)// Returns a reference to the value of type T for positional argument N,// with dim indices specifying which value. No bounds checking is performed// on dim indices.void set_arg0_data(const void* data) {set_arg_data(0, data);}float* arg0_data() {return static_cast<float*>(arg_data(0));}float& arg0(size_t dim0, size_t dim1, size_t dim2, size_t dim3) {return (*static_cast<float(*)[1][160][160][3]>(arg_data(0)))[dim0][dim1][dim2][dim3];}const float* arg0_data() const {return static_cast<const float*>(arg_data(0));}const float& arg0(size_t dim0, size_t dim1, size_t dim2, size_t dim3) const {return (*static_cast<const float(*)[1][160][160][3]>(arg_data(0)))[dim0][dim1][dim2][dim3];}// Result methods for managing output buffers. Buffers are in row-major order.// Must only be called after a successful Run call. There is a set of methods// for each positional result, with the following general form://// T* resultN_data()// Returns the buffer of type T for positional result N.//// T& resultN(...dim indices...)// Returns a reference to the value of type T for positional result N,// with dim indices specifying which value. No bounds checking is performed// on dim indices.//// Unlike the arg methods, there is no set_resultN_data method. The result// buffers are managed internally, and may change after each call to Run.float* result0_data() {return static_cast<float*>(result_data(0));}float& result0(size_t dim0, size_t dim1) {return (*static_cast<float(*)[1][30]>(result_data(0)))[dim0][dim1];}const float* result0_data() const {return static_cast<const float*>(result_data(0));}const float& result0(size_t dim0, size_t dim1) const {return (*static_cast<const float(*)[1][30]>(result_data(0)))[dim0][dim1];}// Methods for managing variable buffers. Buffers are in row-major order.//// For read-write variables we generate the following methods://// void set_var_X_data(T* data)// Sets the buffer for variable X. Must be called before Run if the// allocation mode is RESULTS_PROFILES_AND_TEMPS_ONLY.//// T* var_X_data()// Returns the buffer of type T for variable X. If the allocation mode is// RESULTS_PROFILES_AND_TEMPS_ONLY then this buffer is the same as the// buffer passed to set_var_X_data.//// T& var_X(...dim indices...)// Returns a reference to the value of type T for variable X,// with dim indices specifying which value. No bounds checking is performed// on dim indices.//// For readonly variables we generate the same set of methods, except that we// use `const T` instead of `T`. We use `const T` to avoid erasing the// constness of the buffer passed to `set_var_X_data` but the underlying// buffer is not const (and thus the const can be safely const-cast'ed away)// unless `set_var_X_data` is called with a pointer to constant storage.private:// Number of buffers for the compiled computation.static constexpr size_t kNumBuffers = 50;static const ::xla::cpu_function_runtime::BufferInfo* BufferInfos() {static const ::xla::cpu_function_runtime::BufferInfokBufferInfos[kNumBuffers] = {::xla::cpu_function_runtime::BufferInfo({2293760ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({1228802ULL, 0ULL}),::xla::cpu_function_runtime::BufferInfo({614400ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({602112ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({301056ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({301056ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({301056ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({301056ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({301056ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({172032ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({98304ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({98304ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({98304ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({98304ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({98304ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({73728ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({55296ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({55296ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({55296ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({55296ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({55296ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({55296ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({55296ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({36864ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({24576ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({24576ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({24576ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({24576ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({24576ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({12288ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({6912ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({6144ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({6144ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({6144ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({6144ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({6144ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({2048ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({481ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({33ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({16ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({19ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({19ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({19ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({19ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({19ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({19ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({19ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({19ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({19ULL, ~0ULL}),::xla::cpu_function_runtime::BufferInfo({16571521ULL, ~0ULL})};return kBufferInfos;}static const ::tensorflow::int32* ArgIndexToBufferIndex() {static constexpr ::tensorflow::int32 kArgIndexToBufferIndex[kNumArgs] = {1};return kArgIndexToBufferIndex;}// The 0-based index of the result tuple in the temporary buffers.static constexpr size_t kResultIndex = 38;// Array of names of each positional argument, terminated by nullptr.static const char** StaticArgNames() {return nullptr;}// Array of names of each positional result, terminated by nullptr.static const char** StaticResultNames() {return nullptr;}// Shape of the args and results.static const ::xla::ProgramShapeProto* StaticProgramShape() {static const ::xla::ProgramShapeProto* kShape = nullptr;return kShape;}// Metadata that can be used to pretty-print profile counters.static const ::xla::HloProfilePrinterData* StaticHloProfilePrinterData() {static const ::xla::HloProfilePrinterData* kHloProfilePrinterData =nullptr;return kHloProfilePrinterData;}};// clang-format on
可以看到其中的具体图已经转换为对应运行时指令。
其中的BufferInfo标记的是为.o文件中的具体运行时二进制字块
Step 5: 编写代码调用AOT模型
这一步中需要注意最终形成的.so在什么平台进行使用,当我们在移动端(Android)使用时,与C++进行通讯需要JNI的支持所以在这一步需要重新configure Tensorflow源码配置SDK、NDK支持,具体SDK\NDK对应target自行选择
下文中的调用C++代码将采用复合JNI规范的代码编写
项目Java书写对应native方法生成对应JNI头文件:
|
|
生成头文件com_qihoo_cleandroid_sdk_imageclassfier_core_classfier_process_CustomClassifier.h
|
|
编写C++代码实现模型调用com_qihoo_cleandroid_sdk_imageclassfier_core_classfier_process_CustomClassifier.cc
|
|
此步骤结束
Step 6: 编写BUILD
此步骤中所编写的BUILD文件与Step 3中所编写文件为同一文件
|
|
其中cc_binary中的name即为生成.so的名称该名称应符合JNI规范
注意生成.so动态链接库时需配置linkshared = 1 linkstatic = 1
Step 7: 编译对应平台最终产物 .so
运行命令:bazel build -c opt //tensorflow/compiler/aot/custom:libcustom_interface.so \ --crosstool_top=//external:android/crosstool \ --host_crosstool_top=@bazel_tools//tools/cpp:toolchain \ --cpu=armeabi-v7a
通过--cpu=xxx来控制编译对应平台ABI的.so
至此编译后所有步骤完成
实验结论
通过XLA加速接入移动端对比(其实并没有可比性因为没有控制变量)
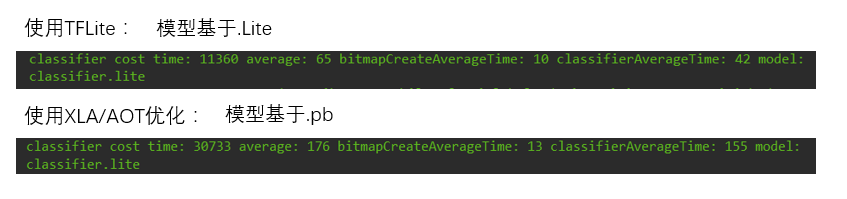
上图中显示了在lite和xla两种方式下使用同一种机型预测174张图片的耗时对比数据
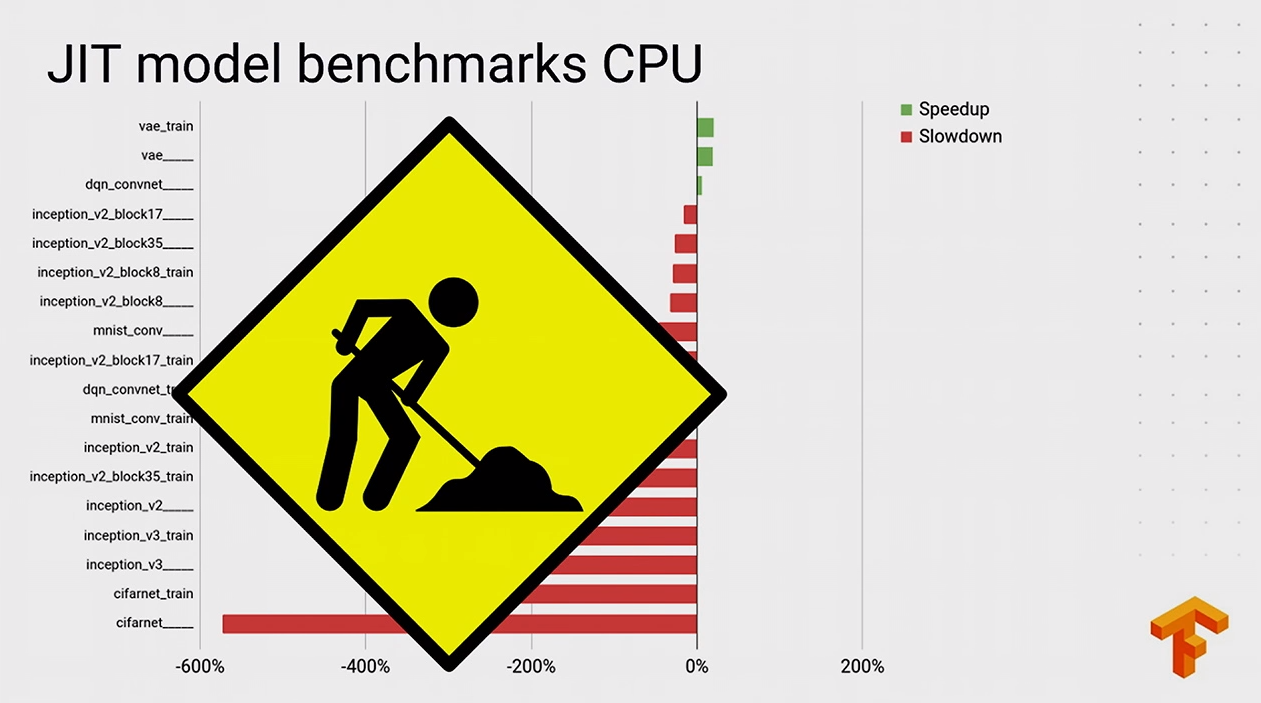
明显lite在这一方面速度非常有优势,但并不代表XLA不起作用,而是恰巧在我们的计算图中使用的卷积网络在这种情况下不适用于XLA进行优化,官方使用JIT的速度对比,其实在JIT的训练时数据和AOT的运行时数据事实上是对应关系恰巧反应了这一关系。
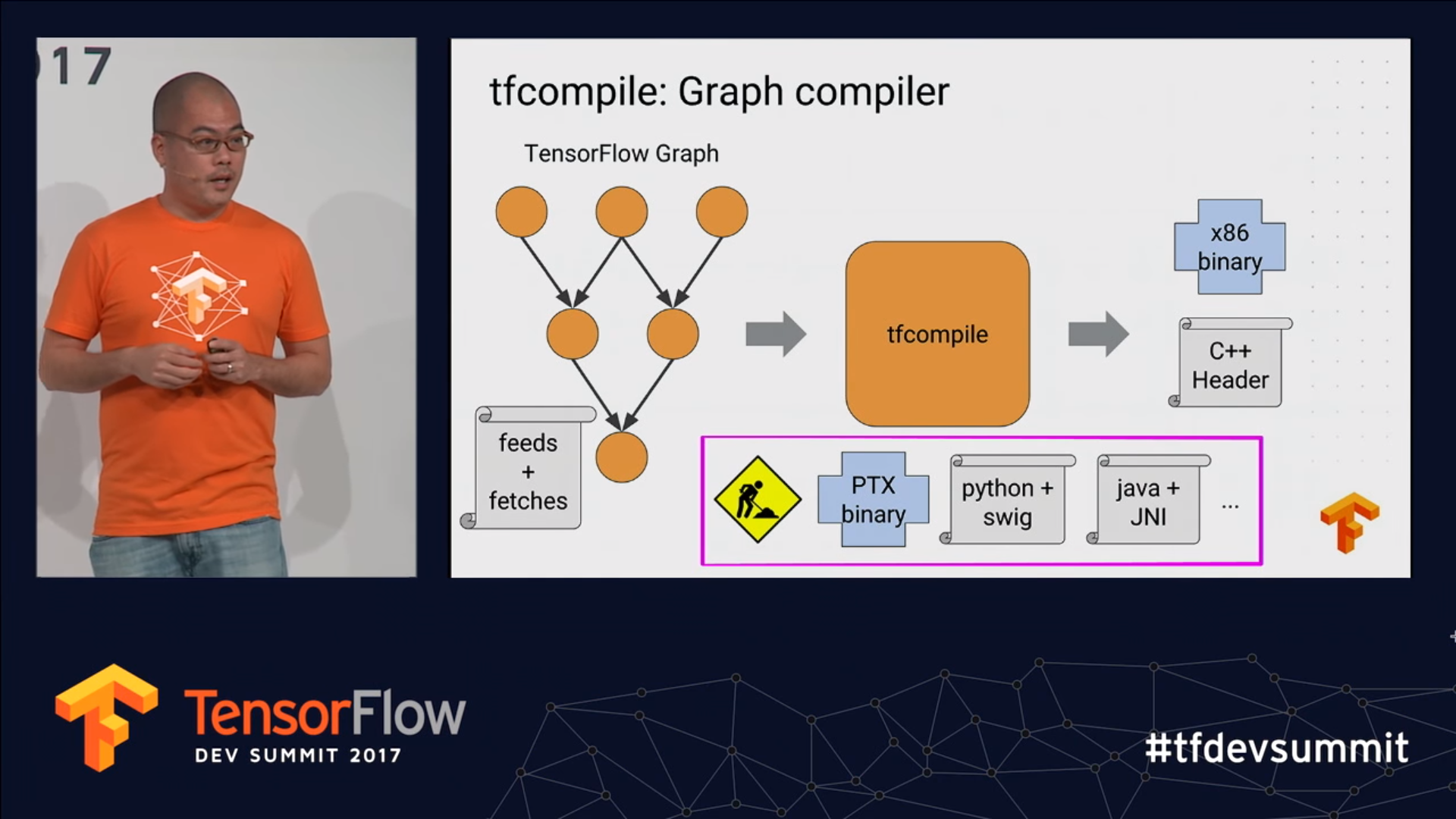
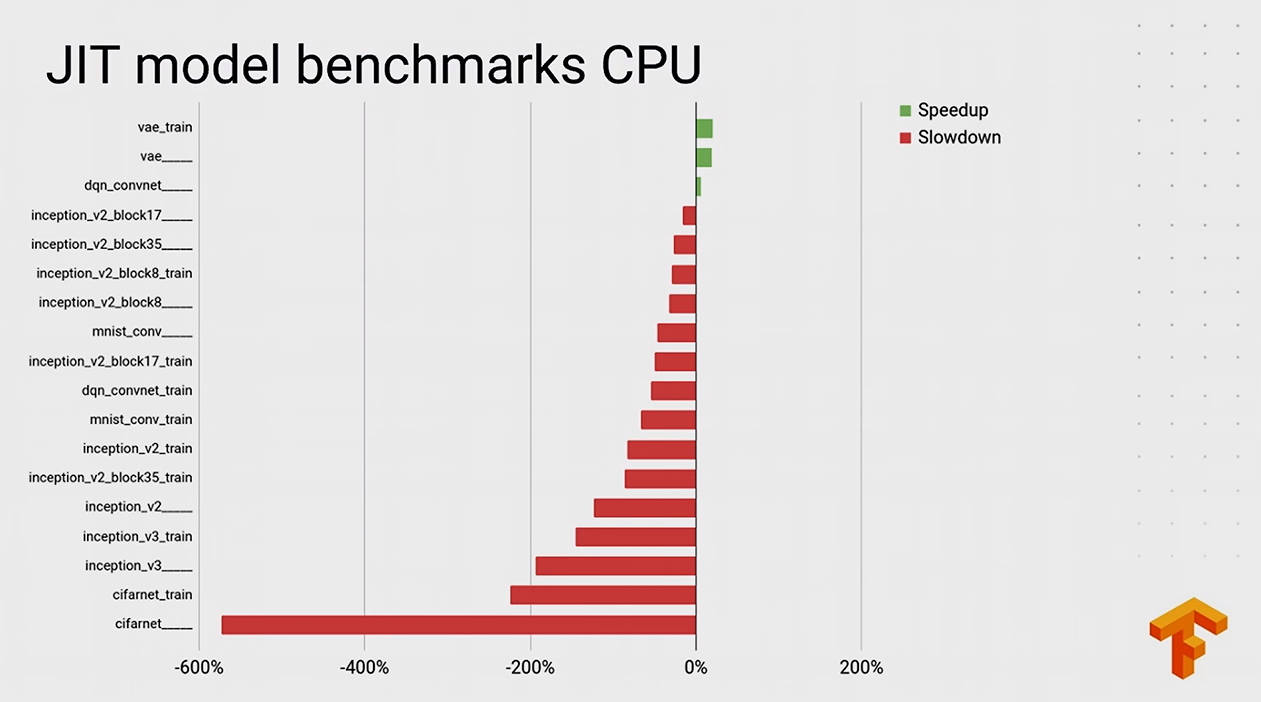
后附几张官方演示图:
Reference
c++ - TensorFlow: cross-compile XLA to Android - Stack Overflow
Danny’s tech notebook | 丹尼技術手札: [XLA 研究] How to use XLA AOT compilation in TensorFlow
Are linkopts propagated from copts and/or deps ? · Issue #7288 · tensorflow/tensorflow
Build TensorFlow for armeabi-v7a and arm64-v8a - zhuiqiuk的专栏 - CSDN博客
